-
적은 부하로 트래픽 처리하기항해 플러스 백엔드 5기 2024. 7. 29. 20:09
1. Caching
Cache란?
- 데이터를 임시로 복사해두는 Storage 계층
- 적은 부하로 API 응답을 빠르게 처리하기 위해서 캐싱을 사용
Cache 사용사례
- DNS : 웹사이트 IP 를 기록해두어 웹사이트 접근을 위한 DNS 조회 수를 줄인다.
- CPU : 자주 접근하는 데이터의 경우, 메모리에 저장해두고 빠르게 접근할 수 있도록 한다.
- CDN : 이미지나 영상과 같은 컨텐츠를 CDN 서버에 저장해두고 애플리케이션에 접근하지 않고 컨텐츠를 가져오도록 해 부하를 줄인다.
2. Server Caching 전략
2.1. 메모리 캐시 (Application Leval)
- 애플리케이션의 메모리에 데이터를 저장해두고 같은 요청에 대해 데이터를 빠르게 접근해 반환함으로서 API 성능 향상 달성
- Spring의 경우 ehcache, caffeine 등 ...
Spring Cacheable Example
@Cacheable("POPULAR_ITEM") @Transactional(readOnly = true) public List<PopularItem> getPopularItems() { return statisticsService.findPopularItems(); } @Scheduled(cron = "0 0 0 * * *") @CacheEvict("POPULAR_ITEM") public void evictPopularItemsCache() { }메모리 캐시의 특징
- 신속성 - 인스턴스의 메모리 캐시 데이터를 저장하므로 속도가 가장 빠르다.
- 저비용 - 인스턴스의 메모리 캐시 데이터를 저장하므로 별도의 네트워크 비용이 발생하지 않는다.
- 휘발성 - 애플리케이션이 종료될 때, 캐시데이터는 삭제됨
- 메모리 부족 - 활성화된 애플리케이션 인스턴스에 데이터를 올려 캐싱하는 방법이므로 메모리 부족으로 인해 비정상 종료로 이어질 수 있다.
- 분산 환경 문제 - 분산 환경에서 서로 다른 서버 인스턴스 간에 데이터 불일치 문제가 발생할 수 있다.
2.2. 별도의 캐시 서비스 (External Level)
- 별도의 캐시 Storage 혹은 이를 담당하는 API 서버를 통해 캐싱 환경 제공
- Radis, Nginx 캐시, CDN 등 ...
캐시 서비스 특징
- 일관성 - 별도의 담당 서비스를 둠으로써 분산 환경 (Multi - Instance) 에서도 동일한 캐시 기능을 제공할 수 있다.
- 안정성 - 외부 캐시 서비스의 Disk에 스냅샷을 저장하여 장애 발생 시 복구가 용이하다.
- 고가용성 - 각 인스턴스에 의존하지 않으므로 분산 환경을 위한 HA 구성이 용이하다.
- 고비용 - 네트워크 통신을 통해 외부의 캐시 서비스와 소통해야 하므로 네트워크 비용 또한 고려애야 한다.
3. 이커머스 시나리오에서의 Caching
3.1. 조회가 오래 걸리는 쿼리
상위 상품 목록 조회 API
- 최근 3일 동안 가장 많이 판매된 상위 5개 상품의 목록을 조회하는 API
- 주문, 주문 목록 테이블 데이터를 기반으로 통계 Query를 수행하여 상위 상품 목록을 추출
- 서비스를 운영할수록 데이터가 쌓이면서 수십만건 이상의 데이터가 쌓이는 경우 통계 Query 속도 저하 이슈 존재
- 여러 사용자가 해당 API 호출하면 호출할수록 DB의 부하는 계속 증가하여 DB에 많은 부하를 줄 수 있음.
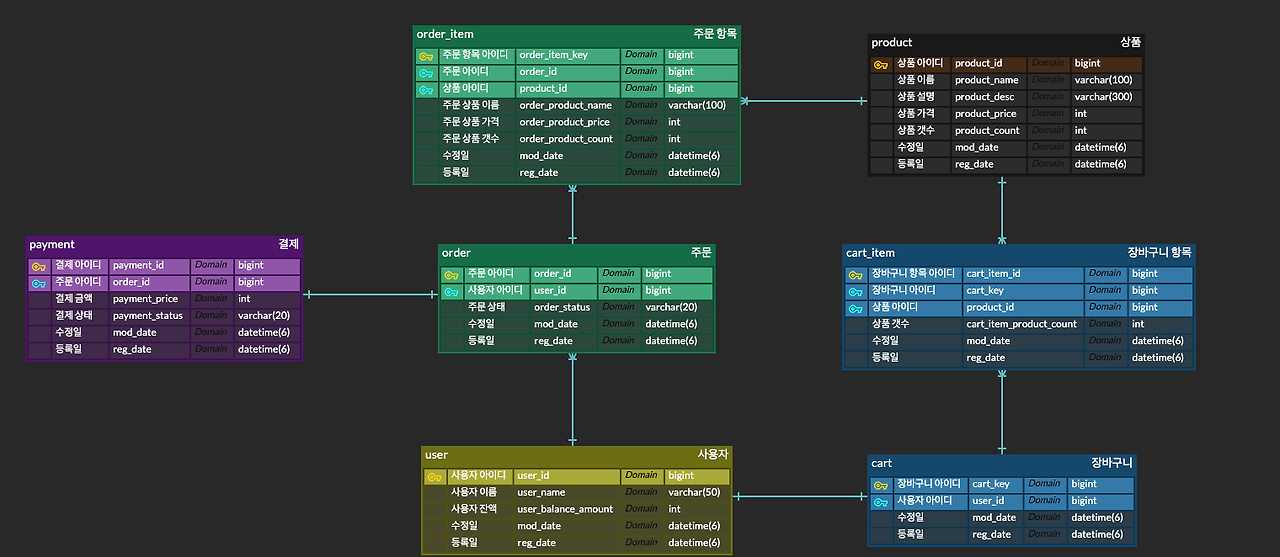
DB ERD
상위 상품 목록 통계 SQL
SELECT oi.product_id, SUM(oi.order_product_count) as order_product_count FROM tb_order_item oi JOIN tb_order o ON oi.order_id = o.order_id WHERE o.order_status = "COMPLETED" AND oi.reg_date >= CURDATE() - INTERVAL 3 DAY GROUP BY oi.product_id ORDER BY order_product_count DESC LIMIT 5;상위 상품 목록 통계 JPA Query
LocalDate threeDaysAgo = LocalDate.now().minusDays(3); List<Tuple> tuples = jpaQueryFactory.select(orderItem.product, orderItem.orderProductCount.sum()) .from(orderItem) .join(orderItem.order, order) .where(order.orderStatus.eq(OrderStatus.COMPLETED), orderItem.createdDateTime.after(threeDaysAgo.atStartOfDay())) .groupBy(orderItem.product) .orderBy(orderItem.orderProductCount.sum().desc()) .limit(5) .fetch();상위 상품 목록 통계 실제 수행 쿼리

select p1_0.product_id, p1_0.reg_date, p1_0.mod_date, p1_0.product_count, p1_0.product_desc, p1_0.product_name, p1_0.product_price, sum(oi1_0.order_product_count) from tb_order_item oi1_0 join tb_order o1_0 on o1_0.order_id=oi1_0.order_id join tb_product p1_0 on p1_0.product_id=oi1_0.product_id where o1_0.order_status = 'COMPLETED' and oi1_0.reg_date > '2024-07-17T19:43:15.747440' group by p1_0.product_id order by sum(oi1_0.order_product_count) desc limit 5쿼리 실행 계획

쿼리 수행시간
- Caching 처리를 하기전 쿼리의 수행시간
- 주문, 주문 목록 테이블 행이 1개씩 존재하는 경우 수행시간

부하 테스트
- 주문, 주문 목록 테이블에 각각 10만건의 데이터가 등록 되어있다.
- JMeter를 사용하여 부하 테스트를 진행 1초 동안 100명의 사용자의 쓰레드를 생성하고 상위 상품 목록조회 API를 1번씩 요청
- 상위 상품 목록 조회하는 요청에서 100명의 사용자가 1번 동시 요청을 보낼시 처리가 평균 4.4초까지 시간이 지연되는 상황 발생

이커머스 특성상, 상위 상품 목록은 메인페이지에 배치되는 조회 기능으로, 유저들이 가장 먼저 반드시 접하게 되는 페이지이기 때문에 요청이 몰릴수 있다.
3.2. Redis를 이용한 로직 이관을 성능 개선할 수 있는 로직 분석
3.2.1. 캐시 적용 대상의 특징
- 빈번한 접근
- 데이터를 처리하기 위해 복잡한 쿼리가 필요한 데이터
- 자주 변경되지 않는 데이터, 데이터 정합성이 중요하지 않은 데이터
3.2.2. 합리적인 이유
- 통계 조회에 사용되는 컬럼들이 인덱스를 걸고 조회 하였음에도 위와 같이 처리지연이 발생
- 사용자가 더 많이 접속하는 경우 DB 커넥션 풀의 제한으로 인해 다수의 스레드가 대기 상태가 되어 시간 지연이 더 발생 할 수 있고, DB를 사용하는 다른 서비스 API 수행 시간에도 영향이 발생할 수 있다.
- 위의 캐시 적용 근거를 토대로 빈번한 조회가 일어날 가능성과 데이터 정합성에 대한 요구사항이 크지 않다고 생각하여 캐싱 적용
4. 캐싱 적용
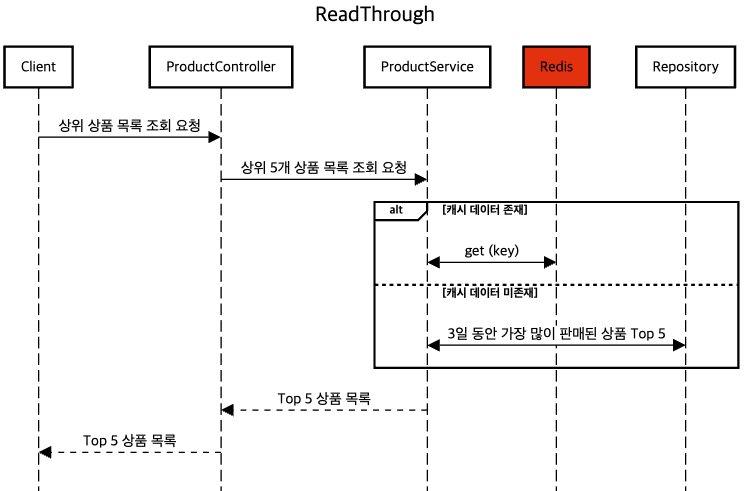
ReadThrough
여러가지 캐싱 전략중 Read Through 방식을 선택
정책으로 정해진 CacheEvict 주기를 통해 캐시를 갱신하는 경우가 아니면, 동일한 상위 상품 목록을 요청이기 때문에,
읽기가 많은 워크로드에 적합한 Read Through 방식을 선택
4.1. Radis 서버 기동
4.1.1. docker-compose.yaml 작성
version: "3.8" services: redis: image: redis:7.0.8-alpine ports: - "6389:6379" command: redis-server /usr/local/etc/redis/redis.conf volumes: # 마운트할 볼륨 설정 - /Users/park/Dev/JIYONG/docker_radis/data - /Users/park/Dev/JIYONG/docker_radis:/usr/local/etc/redis/redis.conf restart: always4.1.2. 작성한 docker-compose.yaml 실행
docker compose up docker-compose.yaml -d
4.1.3. docker ps -a 명령어로 레디스 실행 여부 확인

4.2. 서비스 코드 레디스 캐싱 적용
4.2.1. build.gradle Radis 의존성 추가
// redis implementation 'org.springframework.boot:spring-boot-starter-data-redis'4.2.2. application.yml Redis 서버 정보 추가
spring: data: redis: host: localhost port: 63894.2.2. RedisCacheConfigration 설정
@Configuration @EnableCaching public class RedisCacheConfig { @Bean public CacheManager cacheManager(RedisConnectionFactory cf) { ObjectMapper objectMapper = new ObjectMapper(); objectMapper.registerModule(new JavaTimeModule()); objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.WRAPPER_ARRAY); GenericJackson2JsonRedisSerializer redisSerializer = new GenericJackson2JsonRedisSerializer(objectMapper); RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig() .serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())) .serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer)) // Value Serializer 변경 .entryTtl(Duration.ofHours(1)); // 캐시 수명 1시간 return RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(cf).cacheDefaults(redisCacheConfiguration).build(); } }- entryTtl(Duration.ofHours(1)): 캐시 수명을 1시간으로 설정
해당 설정으로 1시간 마다 캐시 정보가 삭제되고, 다시 데이터베이스에 최신 통계 데이터를 받아오기 때문에 Redis 통계 정보의 정합성은 1시간 마다 갱신이 되도록 정책을 잡았다.
4.2.3. SpringBootApplication @EnableCaching 어노테이션 추가
@EnableCaching // 어노테이션 추가 @SpringBootApplication public class ECommerceApplication { ...4.2.4. 상위 상품 목록 조회 메서드 @Cacheable 어노테이션 설정
- 인기 상품의 상위 5개 목록 정보를 가져온다는 의미에서 value, key를 아래와 같이 설정
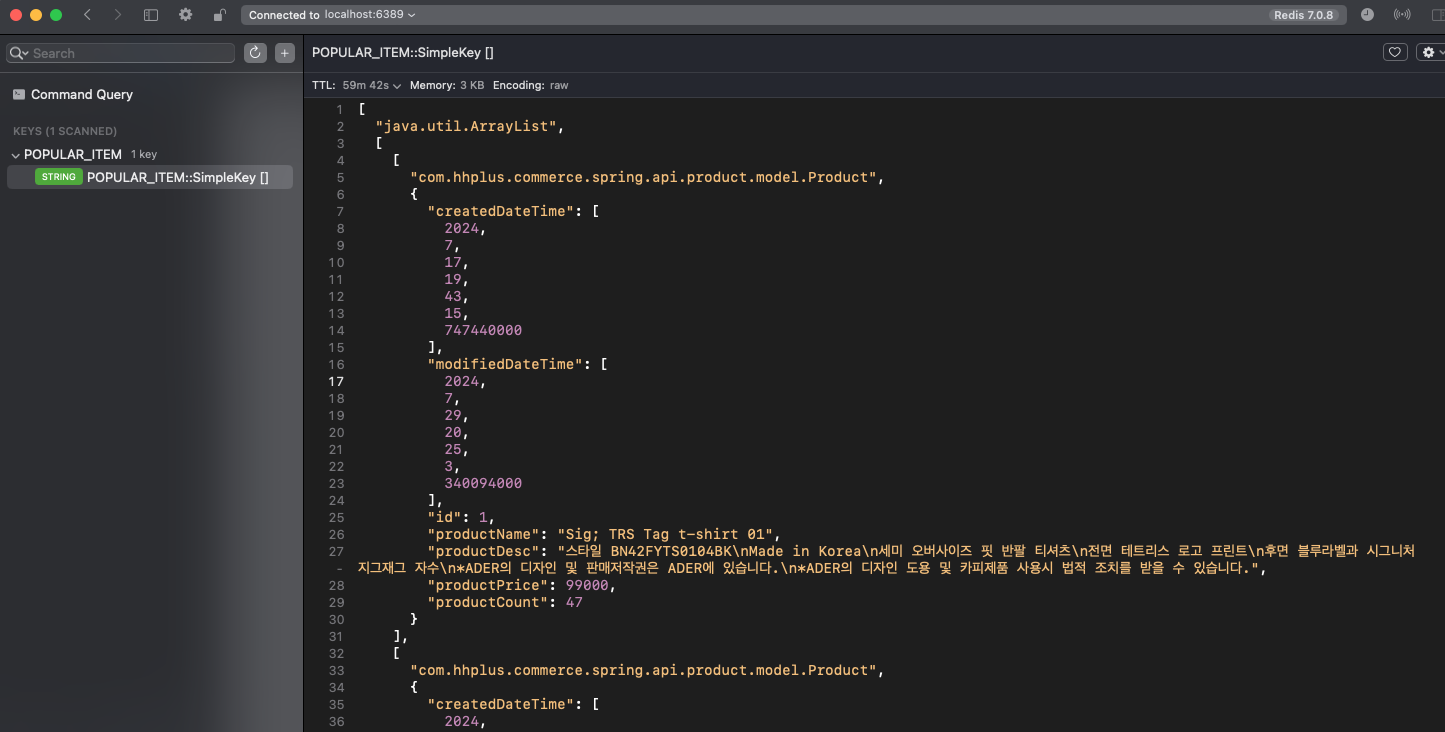
@Transactional(readOnly = true) @Cacheable("POPULAR_ITEM") public List<Product> getPopulars() { return orderItemRepository.selectPopularOrderItems(); }4.2.5 상위 상품 목록 조회 API 요청 후 Radis 적재 데이터 확인
- Medis (Radis UI) Tool 을 통해 Radis 내부에 상위 상품 목록에 통계 데이터 생성 확인
5. 성능 개선
캐싱을 적용한 후 부하 테스트를 진행
- 1초 동안 100명의 사용자의 쓰레드를 생성하고 상위 상품 목록조회 API를 1번씩 요청

레디스 적용 전
- 평균 소요시간: 4455ms (4.4s)
- 최대 소요시간: 8178ms (8.1s)
- 최소 소요시간: 760ms (0.7s)
레디스 적용 후
- 평균 소요시간: 70ms (0.07s)
- 최대 소요시간: 274ms (0.274s)
- 최소 소요시간: 4ms (0.004s)
성능 개선 차이 = 적용 전 평균 소요시간 - 적용 후 평균 소요시간
성능 개선 차이 = 4455 - 70 = 4385
성능 개선 백분율 = (성능 개선 차이 / 적용 전 평균 소요시간) * 100
성능 개선 백분율 = (4385 / 4455) * 100 = 98.42873176%
상위 상품 목록에 Redis를 적용함으로써 사용자는 메인 페이지에 접근할때마다 적게는 0.7초 길게는 최대 8초 이상을 대기하는 문제를 0.2초 이내로 확인할 수 있도록 해결해보았다.
6. 더 개선이 필요한 부분
캐싱이 제거되는 순간 다음 요청을 하는 특정 사용자에게는 시간이 오래걸릴 수 있다.
데이터가 더 추가되면서 많아진다면 특정 사용자는 이전 보다 더 오랜 시간을 기다려야한다.
스케줄러를 적용하여 1시간 마다 캐싱 데이터를 업데이트 해주는 방식으로 수정하고, 사용자들은 캐싱된 데이터만 가져갈 수 있도록 고도화 작업이 필요하다.
'항해 플러스 백엔드 5기' 카테고리의 다른 글
부하를 적절하게 축소하기 (1) (0) 2024.08.04 7주차 회고노트 (0) 2024.08.03 6주차 회고노토 (0) 2024.07.27 e-커머스 서비스 동시성 문제와 극복 (0) 2024.07.22 5주차 회고노트 (0) 2024.07.21